Вступление к посту.Изначально я не хотел разбивать статью на несколько частей, ограничившись одним подробным постом только по окончанию работы. Но обстоятельства вынуждают меня переключиться на другую задачу, так что я решил просто сбросить сюда информацию о том, что уже сделано, иначе наверняка что-то забуду (это не учитывая того, что я УЖЕ забыл).
К тому же объём информации предполагается таким, что его всё равно лучше разбить на несколько частей.
Наслаждайтесь!
Немногим ранее я рассказал о том, как меня увлекло проектирование логических схем в программе Logisim. Потренировавшись на простых схемах, я решил разработать процессор. И чтобы всё по настоящему, с исполнением машинного кода и полнотой Тьюринга.
Для тех, кто не в теме - краткий ликбез. Процессор в электронике - устройство, которому на вход подаются команды и, иногда, их параметры (как правило, закодированные последовательностью битов), на выходе получаются результаты выполнения этих команд над этими данными. Пример простейшего процессора - схема, выполняющая инкремент/декремент поданного на вход значения в зависимости от наличия сигнала на другом входе.
Полнота Тьюринга - свойство исполнителя (т.е. того же процессора) вычислять результат абсолютно любой вычислимой функции. То есть даже простейший тьюринг-полный процессор (если ему предоставить ресурс в виде бесконечной памяти) способен посчитать всё не хуже каких-нибудь пентиумов - только, скорее всего, программа будет сложнее, а исполнение займёт больше шагов. Пример того самого тьюринг-полного процессора - машина Тьюринга, придуманная
знаменитым английским пидорасом великим английским математиком Аланом Тьюрингом; дабы не сверзиться в пучину всяких теорий вычислимости отправлю вас в
Википедию. Впрочем, если вы пропустите этот момент - ничего страшного не случится, надеюсь - я обещаю писать так, чтобы понятно было даже человеку, далёкому от IT (но людям, знакомым с информатикой понять будет легче).
Началу проектирования в Logisim предшествовали обширные прикидки логики на бумаге. Нужно было решить следующие вопросы:
- Разрядность процессора.
- Набор команд.
- Архитектура.
- Порядок следования данных (big-endian или little-endian).
- и ещё куча всего, что просто не приходило сразу в голову.
Сначала я хотел делать четырёхбитный процессор, который, в принципе, покрывал бы ту же машину Тюринга: ну а то, четырёх бит достаточно для операций из 16 команд над алфавитом в 15 символов + 0!
Но я хотел сделать не простенькую игрушку, а что-то, работающее с
архитектурой фон Неймана.
И снова ликбез.
Большинство современных компьютеров реализуют именно архитектуру фон Неймана. В ней программа (набор команд) хранится там же, где и данные, которые программа (вернее, процессор, эту команду исполняющий) обрабатывает. То есть программа сама должна определять, где у неё код, а где - данные, и что из этого и в каком виде надо скармливать процессору. Эта архитектура гибкая (например, программа может сама менять свой код) и просто реализуемая, но, при этом, подвержена ошибкам, вроде переполнения буфера (одна программа бесконтрольно пишет много данных, они не умещаются в отведённый участок памяти, залезают в код другой программы, которая, при выполнении вылетает - или запускает чужой код).
А есть ещё Гарвардская архитектура, в ней код и данные хранятся раздельно. Представьте, что у вас в компе две отдельных устройства ОЗУ, которые друг с другом не взаимодействуют и не пересекаются. И когда программа запускается, её исполняемый код грузится в одно устройство, а данные, с которыми она работает - в другую. Там уже никаких переполнений буфера (по крайней мере, они не должны быть так тривиальны, как в фон Неймане), да и исполнение происходит быстрее (процессору не нужно ждать данных, следующих за инструкцией, они всегда доступны на одном из устройств) - но с гибкостью там никак, да и по реализации она сложнее в несколько раз, в зависимости от подхода. Тем не менее, эта архитектура используется во встраиваемых устройствах, где скорость и надёжность важны, а гибкость - нет.
Реализовать четырёхбитный процессор с архитектурой фон Неймана, конечно, можно. Но возникает слишком уж много ограничений.
Например, если принять, что размер команды равен размеру данных (т.е. тем же четырём битам), то получаем ограничение в 16 инструкций, из которых только минимальный набор инструкций для работы с памятью займёт половину. Затем, процессор должен определить, что обозначают данные, которые ему передали. Константу? Номер регистра? Адрес в памяти? То есть после команды ещё должно быть что-то вроде маркера типа данных - а это ещё по два бита на параметр. И, наконец, четыре бита ограничивают максимально адресуемую память всего 64 байтами (16 адресов по 4 бита).
Всё это решаемо. Можно, например, разграничить размер машинного слова: командное слово считать равным восьми битам, а команды брать четырёхбитные. И адреса тоже брать не четырёхбитные, а восьмибитные. И ещё маркеры типов данных куда-нить пристроить... И дрючиться, высчитывая смещения в памяти, вместо работы с аккуратными идентичными последовательностями.
Но почему бы сразу не сделать восемь бит, благо в Logisim разрядность элементов переключается на лету? На сём и остановился.
Кстати, первый процессор от Intel 4004, хоть и был четырёхбитным, мог адресовать 640 байт памяти, а команд в нём было аж 46. Впрочем, это достигалось тем, что он, как раз, был построен по Гарвардской архитектуре - там с этим проще.
С набором команд тоже пришлось подумать. Делать много команд - усложнять разработку процессора, делать мало команд - усложнять разработку под процессор. Так что я исходил из того, что нужно реализовать самые основные, а потом, по мере необходимости, добавлять остальные.
Затем я посмотрел, с чем будут работать команды. Что будет в моём процессоре:
- Восемь восьмибитных регистров, от A до H (один из которых флаговый, один - адресный, остальные пока решено сделать регистрами общего назначения).
- Память (восьмибитный процессор адресует 256 адресов по восемь бит - итого аж два килобайта).
- Отдельный стек (об этом ниже).
- Ну и просто числа (константы).
Изначально - четыре типа данных, на перечисление которых нужно два бита. Если у каждой команды по два параметра (например, MOV A,B), то получается, что нужно засунуть набор "команда"+4 бита в пространство, кратное восьми битам. Брать шестнадцать бит - несколько избыточно, восемь - как-то маловато (четыре бита на команду - не от этого ли я хотел убежать?).
Но, тем не менее, я выбрал именно восьмибитный размер опкода. Я рассудил так: вряд ли меня хватит для реализации более чем 16 полноценных команд. А если хватит - расширить размер опкода можно будет без проблем.
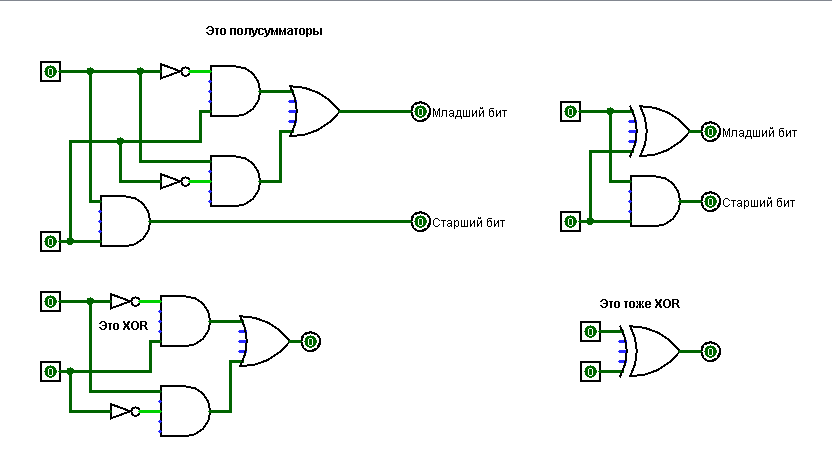
Для начала я решил сделать шесть основных команд. Ниже приведена таблица, описывающая набор инструкций и типы данных, с которыми они работают:
Код (hex) |
Мнемоника |
Действие и параметры |
0x0 |
NOP |
Пропуск такта. |
0x1 |
MOV |
Копирование (не перемещение!) значения в приёмник. MOV [R|S|M],[R|S|M|V] |
0x2 |
XOR |
Побитовый XOR значений. Результат помещается в приёмник. XOR [R|S|M],[R|S|M|V] |
0x3 |
SUM |
Суммирование значений. Результат помещается в приёмник. SUM [R|S|M],[R|S|M|V] |
0x4 |
SHL |
Левое смещение приёмника на указанное количество позиций. SHL [R|S|M],[R|S|M|V] |
0x5 |
SHR |
Правое смещение приёмника на указанное количество позиций. SHL [R|S|M],[R|S|M|V] |
Обозначения: R – регистр (значение указанного регистра), M – память (значение по указанному адресу), V – значение (константа), S – стек (если указан в качестве приёмника – добавление в стек, в качестве отправителя – изъятие из стека).
Оставшиеся десять команд запланированы под условные переходы и остальную математику.
Да, типы данных пронумерованы просто: 00 - константа, 01 - регистр, 10 - стек, 11 - память.
Возьмём байт, скупо отведённый на команду, верхние четыре бита в нём считаем кодом команды, пятый и шестой бит - типом первого операнда, седьмой и восьмой бит - типом второго операнда.
Например, опкод команды MOV, пересылающей данные из регистра в память будет выглядеть так:
00011101. Та же команда, заносящая значение в регистр будет выглядеть как 00010100, а команда левого сдвига верхушки стека на заданное число - 01001000.
Кстати, о стеке. Он у меня необычный по двум причинам (чтобы понять необычность которых, нужно всё-таки знать, что такое
стек).
Первая: я не стал реализовывать стек в основной памяти. Её и так мало (два килобайта, напомню), да плюс на адресацию стека нужно выделять, как минимум, один регистр. При этом совершенно ничего не мешает добавить в нашу схему ещё два килобайта памяти, и использовать под стек уже её (да, это отход от фон Неймана, да...). Это даже не ограничивает многозадачность, ежели таковую когда-нибудь придётся реализовать на этом процессоре, - стековую память точно так же можно поделить на участки по количеству исполняемых программ.
Вторая: у меня нет привычных по ассемблеру для x86 команд PUSH и POP (или аналогичных им). Во-первых, выделять ажно две отдельные команды из имеющегося лимита ой, как не хотелось. Во-вторых, ещё при изучении ассемблера, мне было интересно - а почему бы не сделать именно так? В итоге, команда MOV S,[V|R|M] должна работать аналогично PUSH [V|R|M], а MOV [R|M],S - аналогично POP. Команда MOV S,S хоть и не запрещена, но никакого действия не выполнит (при этом она не будет равна NOP по количеству тактов).
Итого, в результате у меня набралось данных на вполне себе ассемблер для моего ещё не созданного процессора. Ниже приведу примеры команд и трансляцию их в шеснадцатеричный и двоичные коды:
MOV [1Ah],10h (записать число в память)->
0x1C 0x1A 0x10 -> 00011100 00011010 00010000
SUM B,C (прибавить к значению регистра B значение регистра С) ->
0x35 0x01 0x02 -> 00110101 00000001 00000010
XOR S,S (обнулить значение на верхушке стека) -> 0x2A -> 00101010 (параметров у команды нет, то, что работа проводится со стеком, процессор должен понимать из опкода).
и т.д.
И последнее, что осталось - определить и формализовать алгоритм работы процессора. У меня в первом приближении получилось вот что:
1. Считать байт по адресу, на который указывает адресный регистр (adr), в буфер команды, инкрементировав adr.
2. Определить количество параметров команды = pcount.
3. Инкрементируя значение адресного регистра, считывать параметры в соответствующие буфера (n_param в n_buffer) pcount раз.
4. Выполнить команду.
5. Вернуться к шагу 1.
Конечно шаг №4 - это ещё один внутренний алгоритм, который у меня пока ещё не до конца формализован. Причина в том, что при непосредственной реализации схемы по "плавающему" алгоритму ("а, мля, как получится - так и хрен с ним") возникает множество интересных решений и находок, никогда не получившихся бы, следуй я заранее написанному плану.
С теорией, по большей части - всё.
Конец первой части. В следующей - практика: опишу создание парсера команд, контроллера памяти, блока регистров и управляемого цикла.
Продолжение следует.


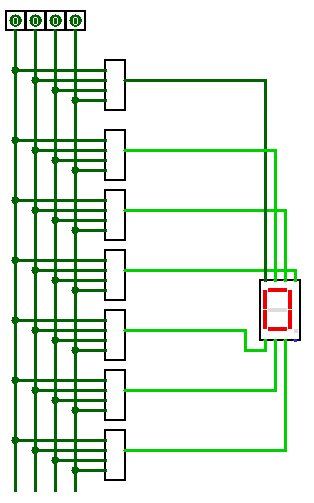
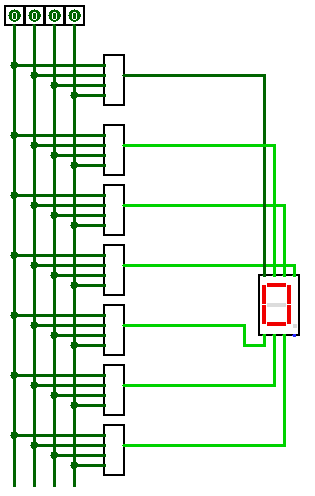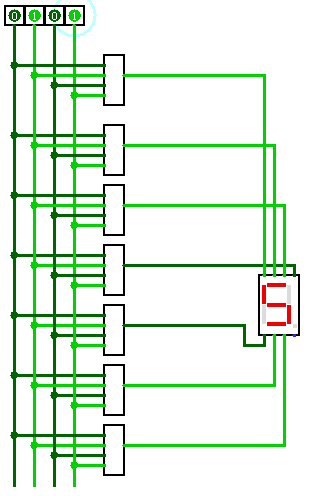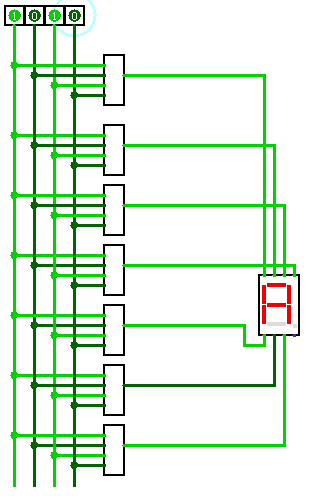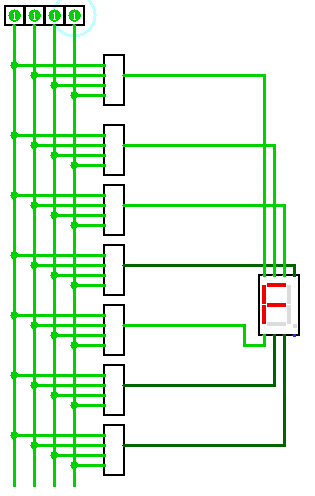
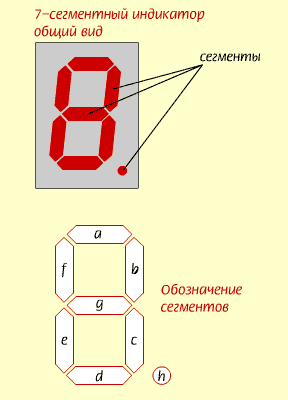 Привлекли они меня тем, что один сегмент (на схеме он отмечен, как b) там не работал, благодаря чему цифры 5 и 9 на этом месте выглядели одинаково. Ну или 6 и 8.
Привлекли они меня тем, что один сегмент (на схеме он отмечен, как b) там не работал, благодаря чему цифры 5 и 9 на этом месте выглядели одинаково. Ну или 6 и 8.